Understand computational resources in Boulder Opal
Understanding the Boulder Opal computing environment and utilizing the compute resources effectively
Based on your Boulder Opal plan, you are allocated machine hours and the maximum number of machines you can spin up to run concurrent calculations. For example, with the Performance plan, you can spin up to 4 machines simultaneously, which corresponds to 4 concurrent calculations. With the Professional plan, you can spin up to 16 machines simultaneously, which corresponds to 16 concurrent calculations. The total number of machine hours consumed is the number of hours aggregated across all machines running in your environment.
In this topic, we will cover how parallel computations are treated and how you can manage your Boulder Opal queue and resources.
Parallel computations
When you submit a calculation request in Boulder Opal, depending on the type of calculation, it will result in one or multiple tasks being added to your organization's queue. Boulder Opal calculations utilize multiprocessing, hence each calculation runs as quickly as possible on a single worker. By design only a single calculation is running at a time on a single worker machine to avoid any memory issues. If your Boulder Opal plan allows for concurrent calculations and enough worker machines are online, the tasks will run in parallel. Visit the Boulder Opal web app to monitor the status of your organization's queue.
Submitting multiple simultaneous calculations
By default, calculations in the Boulder Opal cloud are synchronous, meaning that they will wait until they finish executing before returning the results.
However, some functions support the parameter run_async that you can use to submit multiple asynchronous calculations.
You can learn more about asynchronous job submission in this user guide.
Key considerations when running asynchronous calculations:
- While you can in principle submit as many asynchronous calculations as you want, the actual number of tasks that will run in parallel depends on your Boulder Opal plan and the number of available machines in your environment. You can use
boulderopal.cloud.request_machinesto spin up the machines before submitting the tasks. - When
run_asyncis set toTrue, the request returns aBoulderOpalJobobject. The request is non-blocking, so you can continue other operations. You can check the status of the request usingBoulderOpalJob.get_statusor obtain the result withBoulderOpalJob.get_result. Note thatBoulderOpalJob.get_resultis blocking and will wait for the result to be available.
Managing the queue
In certain scenarios, your calculation may be in the queued state for an unusually long time (for example, longer than 20 minutes). Long queue times can be primarily triggered by:
- Upscaling worker machines.
- Provisioning additional virtual machine instances.
- All allowed machines for the plan are busy running calculations.
Upscaling worker machines
If there are outstanding queued tasks, your Boulder Opal environment will upscale by spinning up new worker machines.
A machine will spin up when a task is in the queue for more than 30 seconds.
For example, in the case of a boulderopal.run_optimization calculation with optimization_count=10 the first worker machine would pick the first task.
And after every 30 seconds if there are outstanding tasks in the queue, a new worker machine will spin up to handle the outstanding tasks.
If each optimization takes about five minutes to run, the system by the end would have spun up 10 worker machines.
This is because at every 30 second interval there would always be a task outstanding in the queue.
Note that, in this scenario, it would take longer for the calculation to complete than if there were already 10 workers spun up and ready.
To reduce wait time you can pre-provision the worker machines.
Pre-provisioning worker machines
Using the boulderopal.cloud.request_machines function, you can choose to avoid default upscaling in your environment.
With this method, you can request the number of worker machines that need to be online before you start processing your calculations.
import boulderopal as bo
bo.cloud.request_machines(machine_count)where machine_count is the number of machines requested to be online (with the maximum set to the number of machines allocated in your plan).
For example,
bo.cloud.request_machines(4)Waiting for 4 machines to be online...
Current environment: 0 machines online, 4 machines pending.
Current environment: 1 machine online, 3 machines pending.
Current environment: 2 machines online, 2 machines pending.
Current environment: 3 machines online, 1 machine pending.
Current environment: 4 machines online, 0 machines pending.
Requested machines (4) are online.
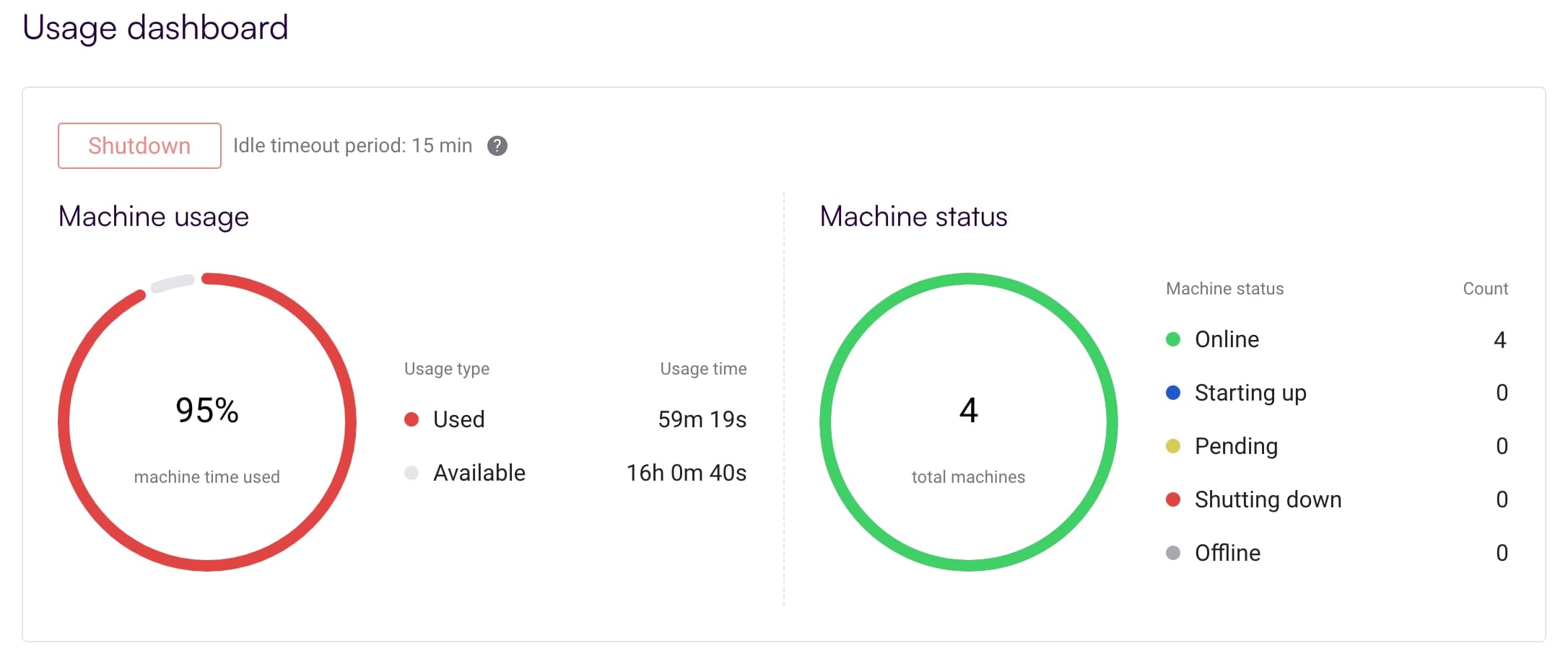
Cancelling calculations and shutting down the environment from the Boulder Opal web app
The Boulder Opal web app allows you to monitor the status of your calculations. You can also manually cancel individual running jobs to preserve resources, or completely shut down the computing environment (cancelling all running jobs).
Cancelling calculations and shutting down the environment from the client
BoulderOpalJob job objects allow you to manage calculations, including retrieving results, checking their status, and canceling them. For more detailed instructions, please refer to this user guide.
If you expect some time will lapse before you submit your next calculation you can preserve resources by shutting down the machines in your cloud environment using the boulderopal.cloud.shut_down_machines function. This function will prevent shutdown if there are ongoing or queued calculations. However, you can force them to shut down regardless by setting the force parameter to True. In that case, any calculations waiting in the queue will be cancelled.
Alternatively, you can check the queue status in your organization's cloud environment with boulderopal.cloud.show_queue_status.
bo.cloud.show_queue_status() Queue status
┏━━━━━━━━━┳━━━━━━━┓
┃ Status ┃ Count ┃
┡━━━━━━━━━╇━━━━━━━┩
│ Queued │ 1 │
├─────────┼───────┤
│ Running │ 0 │
└─────────┴───────┘
You can also use boulderopal.cloud.show_machine_status to show the current status of the machines in your organization's cloud environment.
bo.cloud.show_machine_status() Machine status
┏━━━━━━━━━━━━━━━┳━━━━━━━┓
┃ Status ┃ Count ┃
┡━━━━━━━━━━━━━━━╇━━━━━━━┩
│ Online │ 0 │
├───────────────┼───────┤
│ Starting up │ 1 │
├───────────────┼───────┤
│ Pending │ 0 │
├───────────────┼───────┤
│ Shutting down │ 0 │
├───────────────┼───────┤
│ Offline │ 15 │
└───────────────┴───────┘
Provisioning additional virtual machine (VM) instances
Boulder Opal worker machines are running on Amazon AWS VM instances. There may be a scenario, where underlying VM capacity has run out, hence a new VM instance has to be provisioned. This operation takes time as it requires the underlying AWS instance to be ready before the worker can be set up to execute user calculations.
All allowed machines for the plan are busy running calculations
You can also experience long queue times if you have multiple users running calculations at the same time but your plan does not support enough machines. If you are regularly experiencing this, you can upgrade to a higher plan that meets your needs.
